Belief propagation
Belief propagation is a message passing algorithm for performing inference on graphical models, such as Bayesian networks and Markov random fields. It calculates the marginal distribution for each unobserved node, conditional on any observed nodes. Belief propagation is commonly used in artificial intelligence and information theory and has demonstrated empirical success in numerous applications including low-density parity-check codes, turbo codes, free energy approximation, and satisfiability[1].
The algorithm was first proposed by Judea Pearl in 1982,[2] who formulated this algorithm on trees, and was later extended to polytrees.[3] It has since been shown to be a useful approximate algorithm on general graphs.[4]
If X=(Xv) is a set of discrete random variables with a joint mass function p, the marginal distribution of a single Xi is simply the summation of p over all other variables:
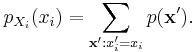
However this quickly becomes computationally prohibitive: if there are 100 binary variables, then one needs to sum over 299 ≈ 6.338 × 1029 possible values. By exploiting the graphical structure, belief propagation allows the marginals to be computed much more efficiently.
Contents |
Description of the sum-product algorithm
Belief propagation operates on a factor graph: a bipartite graph containing nodes corresponding to variables V and factors U, with edges between variables and the factors in which they appear. We can write the joint mass function:
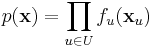
where xu is the vector of neighbouring variable nodes to the factor node u. Any Bayesian network or Markov random field can be represented as a factor graph.
The algorithm works by passing real valued functions called messages along the edges between the nodes. These contain the "influence" that one variable exerts on another. There are two types of messages:
- A message from a variable node v to a factor node u is the product of the messages from all other neighbouring factor nodes (except the recipient; alternatively one can say the recipient sends the message "1"):
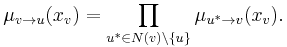
- where N(v) is the set of neighbouring (factor) nodes to v. If
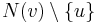 is empty, then
is empty, then 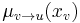 is set to the uniform distribution.
is set to the uniform distribution.
- A message from a factor node u to a variable node v is the product of the factor with messages from all other nodes, marginalised over all variables except xv:
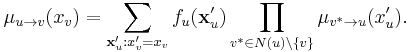
- where N(u) is the set of neighbouring (variable) nodes to u. If
 is empty then
is empty then 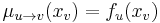 .
.
The name of the algorithm is clear from the previous formula: the complete marginalisation is reduced to a sum of products of simpler terms than the ones appearing in the full joint distribution.
Exact algorithm for trees
The simplest form of the algorithm is when the factor graph is a tree: in this case the algorithm computes exact marginals, and terminates after 2 steps.
Before starting, the graph is orientated by designating one node as the root; any non-root node which is connected to only one other node is called a leaf.
In the first step, messages are passed inwards: starting at the leaves, each node passes a message along the (unique) edge towards the root node. The tree structure guarantees that it is possible to obtain messages from all other adjoining nodes before passing the message on. This continues until the root has obtained messages from all of its adjoining nodes.
The second step involves passing the messages back out: starting at the root, messages are passed in the reverse direction. The algorithm is completed when all leaves have received their messages.
Upon completion, the marginal distribution of each node is proportional to the product of all messages from adjoining factors (missing the normalization constant):
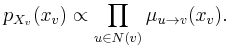
Likewise, the joint marginal distribution of the set of variables belonging to one factor is proportional to the product of the factor and the messages from the variables:
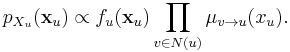
These can be shown by mathematical induction.
Approximate algorithm for general graphs
Curiously, nearly the same algorithm is used in general graphs. The algorithm is then sometimes called "loopy" belief propagation, because graphs typically contain cycles, or loops. The procedure must be adjusted slightly because graphs might not contain any leaves. Instead, one initializes all variable messages to 1 and uses the same message definitions above, updating all messages at every iteration (although messages coming from known leaves or tree-structured subgraphs may no longer need updating after sufficient iterations). It is easy to show that in a tree, the message definitions of this modified procedure will converge to the set of message definitions given above within a number of iterations equal to the diameter of the tree.
The precise conditions under which loopy belief propagation will converge are still not well understood; it is known that graphs containing a single loop will converge to a correct solution.[5] Several sufficient (but not necessary) conditions for convergence of loopy belief propagation to a unique fixed point exist.[6] There exist graphs which will fail to converge, or which will oscillate between multiple states over repeated iterations. Techniques like EXIT charts can provide an approximate visualisation of the progress of belief propagation and an approximate test for convergence.
There are other approximate methods for marginalization including variational methods and Monte Carlo methods.
One method of exact marginalization in general graphs is called the junction tree algorithm, which is simply belief propagation on a modified graph guaranteed to be a tree. The basic premise is to eliminate cycles by clustering them into single nodes.
Related algorithm and complexity issues
A similar algorithm is commonly referred to as the Viterbi algorithm, but also known as the max-product or min-sum algorithm, which solves the related problem of maximization, or most probable explanation. Instead of attempting to solve the marginal, the goal here is to find the values 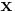 that maximises the global function (i.e. most probable values in a probabilistic setting), and it can be defined using the arg max:
that maximises the global function (i.e. most probable values in a probabilistic setting), and it can be defined using the arg max:
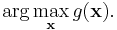
An algorithm that solves this problem is nearly identical to belief propagation, with the sums replaced by maxima in the definitions.
It is worth noting that inference problems like marginalization and maximization are NP-hard to solve exactly and approximately (at least for relative error) in a graphical model. More precisely, the marginalization problem defined above is #P-complete and maximization is NP-complete.
Relation to free energy
The sum-product algorithm is related to the calculation of free energy in thermodynamics. Let Z be the partition function. A probability distribution
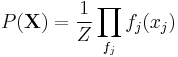
(as per the factor graph representation) can be viewed as a measure of the internal energy present in a system, computed as
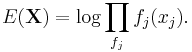
The free energy of the system is then
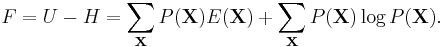
It can then be shown that the points of convergence of the sum-product algorithm represent the points where the free energy in such a system is minimized. Similarly, it can be shown that a fixed point of the iterative belief propagation algorithm in graphs with cycles is a stationary point of a free energy approximation.
Generalized belief propagation (GBP)
Belief propagation algorithms are normally presented as messages update equations on a factor graph, involving messages between variable nodes and their neighboring factor nodes and vice versa. Considering messages between regions in a graph is one way of generalizing the belief propagation algorithm. There are several ways of defining the set of regions in a graph that can exchange messages. One method uses ideas introduced by Kikuchi in the physics literature, and is known as Kikuchi's cluster variation method.
Improvements in the performance of belief propagation algorithms are also achievable by breaking the replicas symmetry in the distributions of the fields (messages). This generalization leads to a new kind of algorithm called survey propagation (SP), which have proved to be very efficient in NP-complete problems like satisfiability[1] and graph coloring.
The cluster variational method and the survey propagation algorithms are two different improvements to belief propagation. The name generalized survey propagation (GSP) is waiting to be assigned to the algorithm that merges both generalizations.
Gaussian belief propagation (GaBP)
Gaussian belief propagation is a variant of the belief propagation algorithm when the underlying distributions are Gaussian. The first work analyzing this special model was the seminal work of Weiss and Freeman [7]
The GaBP algorithm solves the following marginalization problem:
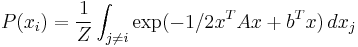
where Z is a normalization constant, A is a symmetric positive definite matrix (inverse covariance matrix a.k.a precision matrix) and b is the shift vector.
Equivalently, it can be shown that using the Gaussian model, the solution of the marginalization problem is equivalent to the MAP assignment problem:
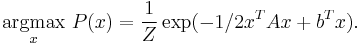
This problem is also equivalent to the following minimization problem of the quadratic form:
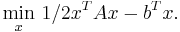
Which is also equivalent to the linear system of equations
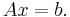
Convergence of the GaBP algorithm is easier to analyze (relatively to the general BP case) and there are two known sufficient convergence conditions. The first one was formulated by Weiss et al. in the year 2000, when the information matrix A is diagonally dominant. The second convergence condition was formulated by Johnson et al.[8] in 2006, when the spectral radius of the matrix
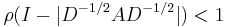
where D = diag(A).
The GaBP algorithm was linked to the linear algebra domain,[9] and it was shown that the GaBP algorithm can be viewed as an iterative algorithm for solving the linear system of equations Ax = b where A is the information matrix and b is the shift vector. The known convergence conditions of the GaBP algorithm are identical to the sufficient conditions of the Jacobi method. Empirically, the GaBP algorithm is shown to converge faster than classical iterative methods like the Jacobi method, the Gauss–Seidel method, successive over-relaxation, and others.[10] Additionally, the GaBP algorithm is shown to be immune to numerical problems of the preconditioned Conjugate Gradient method [11]
Recently, a double-loop technique was introduced to force convergence of the GaBP algorithm to the correct solution even when the sufficient conditions for convergence do not hold. The double loop technique works for either positive definite or column dependent matrices.[12]
Notes
- ^ a b Braunstein, A.; Mézard, R.; Zecchina, R. (2005). "Survey propagation: An algorithm for satisfiability". Random Structures & Algorithms 27 (2): 201–226. doi:10.1002/rsa.20057.
- ^ Pearl, Judea (1982). "Reverend Bayes on inference engines: A distributed hierarchical approach". Proceedings of the Second National Conference on Artificial Intelligence. AAAI-82: Pittsburgh, PA. Menlo Park, California: AAAI Press. pp. 133–136. https://www.aaai.org/Papers/AAAI/1982/AAAI82-032.pdf. Retrieved 2009-03-28.
- ^ Kim, Jin H.; Pearl, Judea (1983). "A computational model for combined causal and diagnostic reasoning in inference systems". Proceedings of the Eighth International Joint Conference on Artificial Intelligence. 1. IJCAI-83: Karlsruhe, Germany. pp. 190–193. http://dli.iiit.ac.in/ijcai/IJCAI-83-VOL-1/PDF/041.pdf. Retrieved 2009-03-28.
- ^ Pearl, Judea (1988). Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference (2nd ed.). San Francisco, CA: Morgan Kaufmann. ISBN 1558604790.
- ^ Weiss, Yair (2000). "Correctness of Local Probability Propagation in Graphical Models with Loops". Neural Computation 12 (1): 1–41. doi:10.1162/089976600300015880.
- ^ Mooij, J; Kappen, H (2007). "Sufficient Conditions for Convergence of the Sum–Product Algorithm". IEEE Transactions on Information Theory 53 (12): 4422–4437. doi:10.1109/TIT.2007.909166.
- ^ Weiss, Yair; Freeman, William T. (October 2001). "Correctness of Belief Propagation in Gaussian Graphical Models of Arbitrary Topology". Neural Computation 13 (10): 2173–2200. doi:10.1162/089976601750541769. PMID 11570995.
- ^ Malioutov, Dmitry M.; Johnson, Jason K.; Willsky, Alan S. (October 2006). "Walk-sums and belief propagation in Gaussian graphical models". Journal of Machine Learning Research 7: 2031–2064. http://jmlr.csail.mit.edu/papers/v7/malioutov06a.html. Retrieved 2009-03-28.
- ^ Gaussian belief propagation solver for systems of linear equations. By O. Shental, D. Bickson, P. H. Siegel, J. K. Wolf, and D. Dolev, IEEE Int. Symp. on Inform. Theory (ISIT), Toronto, Canada, July 2008. http://www.cs.huji.ac.il/labs/danss/p2p/gabp/
- ^ Linear Detection via Belief Propagation. Danny Bickson, Danny Dolev, Ori Shental, Paul H. Siegel and Jack K. Wolf. In the 45th Annual Allerton Conference on Communication, Control, and Computing, Allerton House, Illinois, Sept. 07. http://www.cs.huji.ac.il/labs/danss/p2p/gabp/
- ^ Distributed large scale network utility maximization. D. Bickson, Y. Tock, A. Zymnis, S. Boyd and D. Dolev. In the International symposium on information theory (ISIT), July 2009. http://www.cs.huji.ac.il/labs/danss/p2p/gabp/
- ^ Fixing convergence of Gaussian belief propagation. J. K. Johnson, D. Bickson and D. Dolev. In the International symposium on information theory (ISIT), July 2009. http://www.cs.huji.ac.il/labs/danss/p2p/gabp/
References
- Frey, Brendan (1998). Graphical Models for Machine Learning and Digital Communication. MIT Press
- David J.C. MacKay (2003). Exact Marginalization in Graphs. In David J.C. MacKay, Information Theory, Inference, and Learning Algorithms, pp. 334–340. Cambridge: Cambridge University Press.
- Mackenzie, Dana (2005). Communication Speed Nears Terminal Velocity New Scientist. 9 July 2005. Issue 2507 (Registration required)
- Yedidia, J.S.; Freeman, W.T.; Weiss, Y.; Y. (July 2005). "Constructing free-energy approximations and generalized belief propagation algorithms". IEEE Transactions on Information Theory 51 (7): 2282–2312. doi:10.1109/TIT.2005.850085. http://www.merl.com/publications/TR2004-040/. Retrieved 2009-03-28.
- Yedidia, J.S.; Freeman, W.T.; Y. (January 2003). "Understanding Belief Propagation and Its Generalizations". In Lakemeyer, Gerhard; Nebel, Bernhard. Exploring Artificial Intelligence in the New Millennium. Morgan Kaufmann. pp. 239–236. ISBN 1558608117. http://www.merl.com/publications/TR2001-022/. Retrieved 2009-03-30.
- Bishop, Christopher M (2006). "Chapter 8: Graphical models". Pattern Recognition and Machine Learning. Springer. pp. 359–418. ISBN 0387310738. http://research.microsoft.com/%7Ecmbishop/PRML/Bishop-PRML-sample.pdf. Retrieved 2009-03-30.
- Koch, Volker M. (2007). A Factor Graph Approach to Model-Based Signal Separation --- A tutorial-style dissertation
- Wymeersch, Henk (2007). Iterative Receiver Design. Cambridge University Press. ISBN 0521873150. http://www.cambridge.org/us/catalogue/catalogue.asp?isbn=9780521873154.
- Bickson, Danny. (2009). Gaussian Belief Propagation Resource Page --- Webpage containing recent publications as well as Matlab source code.
- Coughlan, James. (2009). A Tutorial Introduction to Belief Propagation.